들어 가며
최근 Red Hat 은 GraalVM 기술의 등장에 발맞춰 Quarkus 오픈소스 프로젝트를 시작했습니다. 현재 GraalVM 과 함께 지속적으로 발전하는 Quarkus 는 자바 언어의 실행 방식을 확장합니다. 이 글에서는 Quarkus 를 이용해 Apache Camel 자바 애플리케이션이 어떻게 개선되는지 실험해 보고자 합니다.
Quarkus 소개
Red Hat 이 주도하는 오픈소스 프로젝트인 Quarkus 는 자바 오픈소스 및 자바 표준을 기반으로 JVM 및 native image 환경에 최적화된 애플리케이션을 개발 및 빌드할 있게 하는 Kubernetes 를 위한 자바 프레임 워크입니다. Quarkus는, Serverless, Microservice, Container, Kubernetes, FaaS 와 Cloud 를 염두에 두고 설계되어, 자바 애플리케이션을 실행하기 위한 효과적인 해결책을 제공합니다. Quarkus 는 자바 애플리케이션의 메모리 사용량을 줄여주고, 시작 시간을 빠르게 합니다. 이로써 C 나 Golang 등 native image 로 빌드되는 언어 만이 가질 수 있었던 장점을 자바 언어로 손쉽게 구현할 수 있게 합니다.
Red Hat 은 Quarkus 를 Red Hat Runtimes 에 포함해 GA 했습니다.
Apache Camel 소개
Red Hat 이 주도하는 오픈소스인 Apache Camel 은 기업 통합 패턴(EIP, Enterprise Inrgration Patters) 구현체로 경량의 통합 프레임워크입니다. 그러므로 Apache Camel 은 애플리케이션에 함께 패키징이 가능합니다. Apache Camel 은 내부에 라우터 엔진, 프로세서, 컴포넌트, 메시징 시스템을 포함해, 애플리케이션의 내부를 외부 세계와 손쉽게 인터페이스할 수 있게 해줍니다. 즉 Apache Camel 은 애플리케이션, 시스템, 서비스들 사이에서 데이터(Data)와 기능(Function)을 통합(인터페이스)하는 중재자(Mediator)로서 역할합니다.
Red Hat 은 Apache Camel 을 Red Hat Fuse 에 포함해 GA 했습니다.
Quarkus Apache Camel 프로젝트 준비
두 오픈소스 프로젝트 Quarkus 와 Apache Camel 은, Red Hat 주도로, 컨테이너 기반 MSA(Microservice Architecture)와 통합(Integration)을 손쉽게 구현할 수 있게 서로 협력하고 발전하고 있습니다. 그러므로 Quarkus Apache Camel 프로젝트의 생성도 두 기술이 함께 잘 녹아 있는 절차를 따릅니다.
이 문서의 실행 명령들은 필자의 MacBook(macOS) 에서 실행하고 검증했습니다. 그러므로 이 문서를 따라 테스트 하는 독자는 Linux, macOS, Windows 10(WSL 2 설치) 환경에서 테스트할 것을 권장드립니다.
Quarkus Apache Camel 애플리케이션도, 자바 애플리케이션이므로, 자바 애플리케이션 빌드 도구가 필요합니다.
- JDK 11+ 과 JAVA_HOME 경로 등록
- Apache Maven 3.6.2+
Quarkus 로 native image 를 빌드할 경우, 추가로 다음의 플랫폼 환경과 도구가 필요합니다.
- 64 bit OS (Linux 64bit x86 or ARM, Mac OS X 64bit, Windows 64bit)
- 시스템 메모리 14 GB+
- GraalVM Community Edition 20.0.0 과 GRAALVM_HOME 경로 등록
- GraalVM Native image generator (native-image)
GraalVM 은 아래 사이트에서 플랫폼에 맞는 실행 바이너리를 다운로드 합니다.
GraalVM 설치 후, GraalVM native image generator 는 다음 명령을 실행해 설치합니다.
$ cd $GRAALVM_HOME/bin
$ ./gu install native-image
주의
GraalVM 설치 후, 각 플랫폼 별로 native image 빌드를 위한 추가 개발 도구를 설치해야 합니다. 다음 사이트를 참고해 추가 개발 도구를 설치합니다.
위 사이트에 설명이 없는 CentOS 7 나 RHEL 7 플랫폼의 추가 개발 도구는 다음 명령을 실행해 설치합니다.
$ sudo yum group install -y "Development Tools"
$ sudo yum install -y zlib-devel
유스케이스
이 글의 Apache Camel 애플리케이션은 아래와 같은 통합 유스케이스의 구현을 실험했습니다. 이 통합 유스케이스는, CSV 파일을 읽어 JSON 포맷으로 Rest API 에 전달하는 절차로, 기업에서 실무적으로도 사용할 수 있을 것입니다. 실무적 유스케이스를 사용한 이유는 Apache Camel의 실무적 통합 컴포넌트와 의존 라이브러리들이 Quarkus 를 이용해 Native image 로 잘 전환되는 지를 검증하기 위해서였습니다.
- CVS 데이터 생산자는 5초마다 실행됩니다.
- 실행된 데이터 생산자는 두 줄의 CSV UserInfo 레코드를 애플리케이션 실행 디렉토리 아래 input 디렉토리에 userinfo.csv 파일로 기록합니다.
- 파일 소비자는 input 디렉토리에서 생성된 userinfo.csv 파일을 읽고 분할기를 이용해 두 줄의 레코드를 두 개의 UserInfo 자바 객체로 변환 (unmarshal) 합니다.
- 파일 소비자는 UserInfo 자바 객체의 readCount 멤버 변수 값을 파일 소비자가 읽은 순서로 갱신합니다.
- 파일 소비자는 웹서비스의 Rest API(http://localhost:8080/userinfo) 를 호출해 UserInfo 정보를 JSON 메시지로 전송합니다.
- 웹 서비스는 수신한 JSON 메시지를 콘솔 로그로 기록합니다.
- 콘솔 로그에서 CSV 파일 레코드 생성 시각과 파일 소비자가 읽은 순서 등을 확인합니다.
이 유스케이스의 기업 통합 패턴(EIP, Enterprise Integration Patterns) 다이어그램은 다음과 같습니다.

Quarkus Apache Camel 프로젝트
지금까지 기본 설명을 마쳤으므로, 이제 Quarkus Apache Camel 프로젝트 생성 절차를 설명합니다. Apache Camel Quarkus 프로젝트를 가장 손쉽게 시작하는 방법 중 하나는 다음 사이트에서 필요한 컴포넌트를 선택해 Qurkus 기능이 포함된 자바 프로젝트를 생성하는 것입니다.

위 사이트에 접속해 다음과 같이 생성할 프로젝트의 정보를 입력하고, 옵션을 선택합니다. 애플리케이션 상세 (Configure your application details) 에서 다음과 같이 입력합니다.
- Group : com.demo
- Artifact : quarkus-camel-demo
- Build Tool : Maven
확장 선택 (Pick your extensions) 에서 다음의 확장을 선택합니다.
- RESTEasy Jackson
- Camel Quarkus Core
- Camel Quarkus Timer
- Camel Quarkus File
- Camel Quarkus Gson
- Camel Quarkus Bindy
- Camel Quarkus Rest
- Camel Quarkus Http
- Camel Quarkus Log
- Camel Caffeine LRUCache
"Generate your application" 버튼을 클릭해 프로젝트를 생성합니다.
다음과 같은 프로젝트 생성 화면에서 생성된 프로젝트 ZIP 파일을 다운로드합니다.

좀더 간편한 방법으로 Quarkus Code Starter 사이트에서 프로젝트를 생성하지 않고, Quarkus Maven plugin 을 이용해 다음과 같이 명령 행에서 프로젝트를 생성하는 방법도 있습니다. 이 방법을 사용하면 좀더 신속하게 프로젝트를 생성할 수 있습니다.
$ mvn io.quarkus:quarkus-maven-plugin:1.4.1.Final:create \
-DprojectGroupId=com.demo \
-DprojectArtifactId=quarkus-camel-demo \
-DprojectVersion=1.0.0 \
-DclassName="com.demo.UserInfoResource" \
-Dpath="/userinfo" \
-Dextensions="
quarkus-core,
quarkus-resteasy-jackson,
camel-quarkus-timer,
camel-quarkus-file,
camel-quarkus-gson,
camel-quarkus-bindy,
camel-quarkus-rest,
camel-quarkus-http,
camel-quarkus-log,
camel-quarkus-caffeine-lrucache"
위 과정을 마친 후, 선호하는 통합 개발 환경(IDE) 에 프로젝트를 임포트해 개발을 시작합니다.
이 과정을 통해 완성된 프로젝트와 추가된 소스를 확인하려면 필자의 소스를 참조해 주십시오.
Apache Camel DSL
위 통합 유스케이스는 Apache Camel Java DSL 로 다음과 같이 구현할 수 있습니다. (Apache Camel DSL 은 필자의 바른모 블로그 나 Camel in Action 을 참조해 주십시오.)
package com.demo;
import org.apache.camel.Exchange;
import org.apache.camel.Processor;
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.dataformat.bindy.csv.BindyCsvDataFormat;
import org.apache.camel.model.rest.RestBindingMode;
import java.util.concurrent.atomic.AtomicInteger;
public class CamelRouteBuilder extends RouteBuilder {
static AtomicInteger readCount = new AtomicInteger();
public void configure() {
BindyCsvDataFormat biindy = new BindyCsvDataFormat(com.demo.UserInfo.class);
restConfiguration()
.host("localhost")
.port(8080)
.jsonDataFormat("json-gson")
.bindingMode(RestBindingMode.json);
from("timer://csv?period=5000")
.routeId("csvProducerRoute")
.setBody(simple("Gildong,Hong,${date:now}\nWoochi,Jun,${date:now}"))
.to("file://input?fileName=userinfo.csv")
.log("New userinfo.csv saved.");
from("file://input?fileName=userinfo.csv&delete=true")
.routeId("csvConsumerRoute")
.log("Loaded userinfo.csv records\n${body}")
.unmarshal(biindy)
.split(body())
.parallelProcessing()
.process(new Processor() {
@Override
public void process(Exchange exchange) throws Exception {
UserInfo userInfo = exchange.getIn().getBody(UserInfo.class);
userInfo.setReadCount(readCount.incrementAndGet());
}
})
.log("Call Rest API using ${body} ...")
.to("rest:post:userinfo");
}
}
Quarkus 는, 위와 같이 Camel DSL 클래스를 구현만 하면, 애플리케이션 시작 시 Camel DSL 자바 클래스를 자동으로 찾아 실행합니다. Spring Boot 의 경우, 애플리케이션 시작에 Camel DSL 을 실행하기 위해서는, @Service 나 @Component 애노테이션을 Camel DSL 클래스에 지정해 Spring Bean 임을 선언해야 합니다. 그런데 Quarkus 는 이런 애노테이션 지정 없이 클래스가 RouteBuilder 를 상속하면 자동으로 실행됩니다. Quarkus 의 이런 관례는, 처음 Quarkus 를 경험하는 개발자들에게 도리어 혼란을 야기할 수도 있을 것 같습니다. 관례 와 의도 가 조화롭게 잘 정의된 프레임워크가 좋은 프레임워크이기 때문입니다.
Rest API 서비스
위 통합 유스케이스의 Rest API 서비스는 Java EE JAX-RS 표준 애노테이션을 이용해 다음과 같이 구현합니다. (참고로 Lombok 프레임워크도 Quarkus 에서 native image 로 잘 빌드되는지 실험하기 위해 일부러 사용했습니다.)
package com.demo;
import lombok.extern.slf4j.Slf4j;
import javax.ws.rs.Consumes;
import javax.ws.rs.POST;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
@Slf4j
@Path("/userinfo")
public class UserInfoResource {
@POST
@Consumes(MediaType.APPLICATION_JSON)
@Produces(MediaType.APPLICATION_JSON)
public UserInfo hello(UserInfo userInfo) {
log.info("Received : " + userInfo);
return userInfo;
}
}
Quarkus 가 사용하는 Java EE JAX-RS 애노테이션은, Spring Web 애노테이션과 다르지만, 가급적 표준을 따르는 것이 올바른 방법일 것 같기도 합니다. 그럼에도 Quarkus 프로젝트에서 조만간 Spring 호환 애노테이션도 제공할 것으로 보이는 데, 그렇게 되면 두 애노테이션 중 편리한 애노테이션을 사용할 수 있을 것입니다. 참고로 Quarkus 는 기본적으로 Vert.x 기술을 기반해 웹 서비스를 제공한다는 점도 알아두면 유용할 것입니다.
애플리케이션 빌드
Quarkus 를 이용하면 자바 애플리케이션을 세 가지 실행 형태로 빌드할 수 있습니다. 하나는 전통적인 Jar 실행 패키지고, 하나는 Native image 실행 바이너리입니다. 그리고 Container image 로도 빌드합니다.
Jar 빌드
Jar 빌드는 전통적인 자바 빌드 방법으로 아래와 같이 maven 명령을 이용합니다. (-DskipTests 로 테스트 단계를 건너뛰는 옵션을 지정했습니다. 이 옵션을 사용하지 않으면 테스트가 진행됩니다.)
$ ./mvnw package -DskipTests
$ ls -alh target
...
-rw-r--r-- 1 jcha staff 290K 5 5 01:38 quarkus-camel-demo-1.0.0-runner.jar
-rw-r--r-- 1 jcha staff 22K 5 5 01:38 quarkus-camel-demo-1.0.0.jar
drwxr-xr-x 129 jcha staff 4.0K 5 5 01:38 lib
...
$ du -sh lib
37M lib
...
빌드가 성공하면 실행 jar 파일(*-runner.jar), 클래스를 포함한 jar, 그리고 의존 라이브러리를 포함하는 lib 디렉토리가 생성됩니다. 생성된 실행 jar 파일의 크기는 290 KB 크기로, 실제 소스가 컴파일된 jar 22 KB 와 Quarkus 클래스 268 KB 가 포함됩니다. Quarkus 클래스 영역은 애플리케이션이 커져도 동일한 크기를 가질 것입니다. Quarkus 클래스들은 실행 jar 를 실행하면 실제 애플리케이션을 탑재하고 시작시킵니다. 실행은 아래 Jar 패키지 실행을 참조해 주십시오.
Native image 빌드
Native image 빌드는 자바 애플리케이션이 JVM 의존 없는 단일 실행 바이너러로 빌드되는 것을 의미합니다. 즉 단일 실행 바이너리가 JVM 기능을 포함합니다. 빌드 방법은 아래와 같이 Maven 을 이용해 빌드합니다. Jar 빌드와 다른 점은 Maven 빌드에 native 프로파일 옵션인 -Pnative 을 추가로 지정했다는 점입니다. Native image 빌드에 사용하는 Maven native 프로파일은 Quarkus Code Starter 나 Quarkus maven plugin 이 프로젝트 생성할 때 Maven pom.xml 에 자동으로 구성합니다.
$ ./mvnw package -Pnative -DskipTests
...
[quarkus-camel-demo-1.0.0-runner:6453] [total]: 147,334.21 ms, 11.75 GB
...
$ ls -alh target
drwxr-xr-x 4 jcha staff 128B 5 5 10:29 quarkus-camel-demo-1.0.0-native-image-source-jar
-rwxr-xr-x 1 jcha staff 87M 5 5 10:29 quarkus-camel-demo-1.0.0-runner
...
$ file target/quarkus-camel-demo-1.0.0-runner
target/quarkus-camel-demo-1.0.0-runner: Mach-O 64-bit executable x86_64
$ otool -L target/quarkus-camel-demo-1.0.0-runner
target/quarkus-camel-demo-1.0.0-runner:
/usr/lib/libc++.1.dylib (compatibility version 1.0.0, current version 902.1.0)
/System/Library/Frameworks/CoreServices.framework/Versions/A/CoreServices (compatibility version 1.0.0, current version 1069.22.0)
/System/Library/Frameworks/CoreFoundation.framework/Versions/A/CoreFoundation (compatibility version 150.0.0, current version 1675.129.0)
/usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 1281.100.1)
/usr/lib/libz.1.dylib (compatibility version 1.0.0, current version 1.2.11)
Native image 빌드는 상당하 많은 시스템 메모리를 요구합니다. 필자의 개발 PC(MacBook) 빌드에서는 최종적으로 11.75 GB의 시스템 메모리가 사용됐다고 기록이 남았습니다. GraalVM native image 문서를 보면 Native image 빌드를 위해서는 시스템 메모리가 14 GB 이상이 필요하다고 합니다. GraalVM 팀은 빌드 과정 메모리 최적화를 안한 것인지 못하는 것인지 궁금합니다. (이런 이유로 필자의 라즈베리 파이에서는 빌드 환경은 구성 가능했지만 직접적으로 Native image 빌드는 수행할 수 없었습니다. )
빌드가 성공하면 실행 바이너리 파일(*-runner)과 자바 애플리케이션 클래스를 포함한 jar 파일이 생성됩니다. Native image 빌드로 생성된 실행 바이너리는 87 MB 크기로 JVM 기능을 포함합니다. 실행 바이너리는 jar 패키지, 의존 jar, 그리고 JVM 영역을 모두 포함하므로, 애플리케이션 클래스 jar 와 lib 37 MB 을 빼면, 실행 바이너리에서 순수 JVM 영역은 약 50 MB 정도로 볼 수 있을 것입니다.
실행 바이너리 실행 시, 모든 실행 바이너리가 실행 메모리에 적재되지는 않으므로, 실제 시스템 메모리 사용은 실행 바이너리 크기보다 훨씬 적습니다.
필자는 개발 PC 는 MacBook 이므로, 생성된 실행 바리너리를 file 명령을 확인해 본 결과, 파일 형식이 Mach-O 64-bit executable x86_64 인 Native image 파일(*-runner)임을 확인한 수 있었습니다.
CentOS 7 에서도 빌드를 해 보았는데, 이 경우 실행 바이너리의 의존은 다음과 같았습니다.
$ ldd target/quarkus-camel-demo-1.0.0-runner
linux-vdso.so.1 => (0x00007ffdc6f93000)
libstdc++.so.6 => /lib64/libstdc++.so.6 (0x00007faa18c05000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007faa189e9000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007faa187e5000)
libz.so.1 => /lib64/libz.so.1 (0x00007faa185cf000)
librt.so.1 => /lib64/librt.so.1 (0x00007faa183c7000)
libc.so.6 => /lib64/libc.so.6 (0x00007faa17ff9000)
libm.so.6 => /lib64/libm.so.6 (0x00007faa17cf7000)
/lib64/ld-linux-x86-64.so.2 (0x00007faa18f0c000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007faa17ae1000)
위 결과로 Native image 로 빌드된 자바 애플리케이션은 플랫폼의 기본 라이브러리들에 의존하고 있음을 알 수 있었습니다. 그런데 만약 자바 애플리케이션의 Native image 영역 중 반드시 최적화가 필요하지 않은 JVM 영역이 플랫폼에 맞도록 공유 라이브러리로 분리될 수 있다면, 자바 애플리케이션의 Native image 크기를 더 줄일 수 있지 않을까 생각해 봅니다.
Container image 빌드
Container image 빌드는 Native image 빌드를 실행한 플랫폼 OS 의 실행 바이너리가 아닌 컨테이너 실행 환경인 Linux 의 실행 바이너리를 생성한다는 점이 다릅니다.
필자는 필자의 개발 PC 에서 Container image 빌드를 하기 위해 Mac 용 “Docker desktop” 을 설치했습니다. 다음은 필자가 사용한 “Docker desktop” 버전은 다음과 같습니다.

Container image 빌드는 Native image 빌드에 -Dquarkus.native.container-build=true 옵션을 추가하면 됩니다.
$ ./mvnw package -Pnative -Dquarkus.native.container-build=true -DskipTests
...
[quarkus-camel-demo-1.0.0-runner:24] [total]: 181,112.75 ms
[INFO] [io.quarkus.deployment.QuarkusAugmentor] Quarkus augmentation completed in 191029ms
...
$ ls -alh target
drwxr-xr-x 4 jcha staff 128B 5 7 18:57 quarkus-camel-demo-1.0.0-native-image-source-jar
-rwxr-xr-x 1 jcha staff 89M 5 7 18:57 quarkus-camel-demo-1.0.0-runner
...
$ file target/quarkus-camel-demo-1.0.0-runner
target/quarkus-camel-demo-1.0.0-runner: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=b951368d112bf5a6589d0c6fe8e67712cd9ce87f, with debug_info, not stripped
$ otool -L target/quarkus-camel-demo-1.0.0-runner
llvm-objdump: error: target/quarkus-camel-demo-1.0.0-runner': object is not a Mach-O file type.
위 콘솔 로그에서 보듯이 필자의 개발 PC 에서는 Conatiner image 빌드가 약 3분 정도 소요됐습니다. 그리고 필자의 개발 PC 가 MacBook(macOS) 임에도 불구하고, 생성된 실행 바이너리(*-runner)의 파일 형식은 ELF 64-bit LSB executable 로 컨테이너 이미지에 포함할 수 있는 Linux 용 바이너리가 생성됐습니다. 기대한 대로 생성된 실행 바이너리는 macOS 의 otool 로도 읽을 수 없습니다.
생성된 컨테이너 용 실행 바이너리는 다음 절차를 수행해 최종적으로 컨테이너 이미지로 빌드합니다.
$ docker build -f src/main/docker/Dockerfile.native -t quarkus/quarkus-camel-demo .
...
Successfully built 7a6b92b9eaa3
Successfully tagged quarkus/quarkus-camel-demo:latest
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
quarkus/quarkus-camel-demo latest 7a6b92b9eaa3 About a minute ago 294MB
registry.access.redhat.com/ubi8/ubi-minimal 8.1 91d23a64fdf2 5 weeks ago 107MB
...
최종적으로 생성된 자바 애플리케이션 컨테이너 이미지는 294MB 크기입니다. 이 컨테이너 이미지의 베이스 이미지인 레드햇 유니버셜 베이스 이미지(ubi-minimal:8.1)는 107 MB 입니다.
애플리케이션 실행
이 글에서 자바 애플리케이션은 세 가지 형태로 빌드됐습니다. 하나는 전통적인 Jar 패키지이고 다른 하나는 Native image 이고, 마지막으로 Container image 입니다. 각각의 실행 방법은 다음과 같습니다.
Jar 애플리케이션 실행
다음은 필자의 개발 PC 에서 빌드된 jar 실행 패키지 자바 애플리케이션을 실행한 결과입니다.
$ java -jar target/quarkus-camel-demo-1.0.0-runner.jar
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
--\___\_\____/_/ |_/_/|_/_/|_|\____/___/
2020-05-05 01:38:39,595 INFO [org.apa.cam.sup.LRUCacheFactory] (main) Detected and using LURCacheFactory: camel-caffeine-lrucache
2020-05-05 01:38:39,800 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Apache Camel 3.1.0 (CamelContext: camel-1) is starting
2020-05-05 01:38:39,802 INFO [org.apa.cam.imp.eng.DefaultManagementStrategy] (main) JMX is disabled
2020-05-05 01:38:39,889 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) StreamCaching is not in use. If using streams then its recommended to enable stream caching. See more details at http://camel.apache.org/stream-caching.html
2020-05-05 01:38:40,056 INFO [org.apa.cam.com.htt.HttpComponent] (main) Created ClientConnectionManager org.apache.http.impl.conn.PoolingHttpClientConnectionManager@6724cdec
2020-05-05 01:38:40,115 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Route: csvProducerRoute started and consuming from: timer://csv
2020-05-05 01:38:40,120 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Route: csvConsumerRoute started and consuming from: file://input
2020-05-05 01:38:40,125 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Total 2 routes, of which 2 are started
2020-05-05 01:38:40,127 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Apache Camel 3.1.0 (CamelContext: camel-1) started in 0.325 seconds
...
Quakus 로 빌드한 Jar 실행 패키지 자바 애플리케이션의 시작 시간은 0.325 초였습니다. 일반적으로 자바 애플리케이션의 시작은 JVM 의 실행 초기화와 프레임워크의 초기화를 포함합니다. 그러므로 최소한 수 초 정도 시작 시간이 필요합니다. 그런데 이 과정도 Qurkus 는 최적해 실행 패키지의 시작 시간이 개선됐음을 볼 수 있었습니다.
Native image 애플리케이션 실행
다음은 필자의 개발 PC 에서 Native image 자바 애플리케이션을 실행한 결과입니다.
$ ./target/quarkus-camel-demo-1.0.0-runner
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
--\___\_\____/_/ |_/_/|_/_/|_|\____/___/
2020-05-05 12:51:21,838 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Apache Camel 3.1.0 (CamelContext: camel-1) is starting
2020-05-05 12:51:21,838 INFO [org.apa.cam.imp.eng.DefaultManagementStrategy] (main) JMX is disabled
2020-05-05 12:51:21,842 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) StreamCaching is not in use. If using streams then its recommended to enable stream caching. See more details at http://camel.apache.org/stream-caching.html
2020-05-05 12:51:21,844 INFO [org.apa.cam.com.htt.HttpComponent] (main) Created ClientConnectionManager org.apache.http.impl.conn.PoolingHttpClientConnectionManager@1127f7828
2020-05-05 12:51:21,851 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Route: csvProducerRoute started and consuming from: timer://csv
2020-05-05 12:51:21,851 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Route: csvConsumerRoute started and consuming from: file://input
2020-05-05 12:51:21,851 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Total 2 routes, of which 2 are started
2020-05-05 12:51:21,851 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Apache Camel 3.1.0 (CamelContext: camel-1) started in 0.013 seconds
...
애플리케이션 실행 결과, Native image 형식으로 빌드한 자바 애플리케이션의 시작 시간은 0.013 초였습니다. 즉 Native image 자바 애플리케이션은 약 13 밀리초 만에 시작을 완료했습니다. 일반적인 자바 애플리케이션은 시작 시간이 수 초 이상입니다. 이 결과로 Native image 로 빌드된 자바 애플리케이션은 기존의 자바 애플리케이션보다 약 100 배 시작 시간이 빨라짐을 확인할 수 있었습니다.
애플리케이션의 실행 시간 (및 종료 시간) 이 빨라지면 신속한 배포가 가능하고, 배포에 따른 중단 시간을 단축할 수 있습니다. 이런 기술적 특징은 Serverless 등 컨테이너 기술에 필수적 조건입니다.
Container image 애플리케이션 실행
다음은 필자의 개발 PC 에서 빌드된 자바 애플리케이션 컨테이너 이미지를 실행한 결과입니다.
$ docker run -i --rm -p 8080:8080 quarkus/quarkus-camel-demo
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
--\___\_\____/_/ |_/_/|_/_/|_|\____/___/
2020-05-07 10:19:24,690 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Apache Camel 3.1.0 (CamelContext: camel-1) is starting
2020-05-07 10:19:24,690 INFO [org.apa.cam.imp.eng.DefaultManagementStrategy] (main) JMX is disabled
2020-05-07 10:19:24,692 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) StreamCaching is not in use. If using streams then its recommended to enable stream caching. See more details at http://camel.apache.org/stream-caching.html
2020-05-07 10:19:24,693 INFO [org.apa.cam.com.htt.HttpComponent] (main) Created ClientConnectionManager org.apache.http.impl.conn.PoolingHttpClientConnectionManager@7f9091eb2868
2020-05-07 10:19:24,699 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Route: csvProducerRoute started and consuming from: timer://csv
2020-05-07 10:19:24,699 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Route: csvConsumerRoute started and consuming from: file://input
2020-05-07 10:19:24,700 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Total 2 routes, of which 2 are started
2020-05-07 10:19:24,701 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Apache Camel 3.1.0 (CamelContext: camel-1) started in 0.010 seconds
2020-05-07 10:19:24,707 INFO [io.quarkus] (main) =quarkus-camel-demo 1.0.0 (powered by Quarkus 1.4.1.Final) started in 0.027s.
...
Container image 실행 결과도 Native image 형식으로 빌드한 자바 애플리케이션의 시작 시간은 0.013 초과 유사하게 0.027 초 였습니다. 즉 Container image 자바 애플리케이션은 약 27 밀리초 만에 시작을 완료했습니다. Native image 를 컨테이너 이미지로 빌드하면서 컨테이너 시작 단계가 포함돼 순수 Native image 시작 시간보다 길어지긴 했지만, Quarkus 를 이용해 Native image 을 Container image 로 전환한 자바 애플리케이션은 초 당 40 개 정도 실행 할 수 있다는 가능성을 확인할 수 있었습니다.
애플리케이션 실행 시간 비교
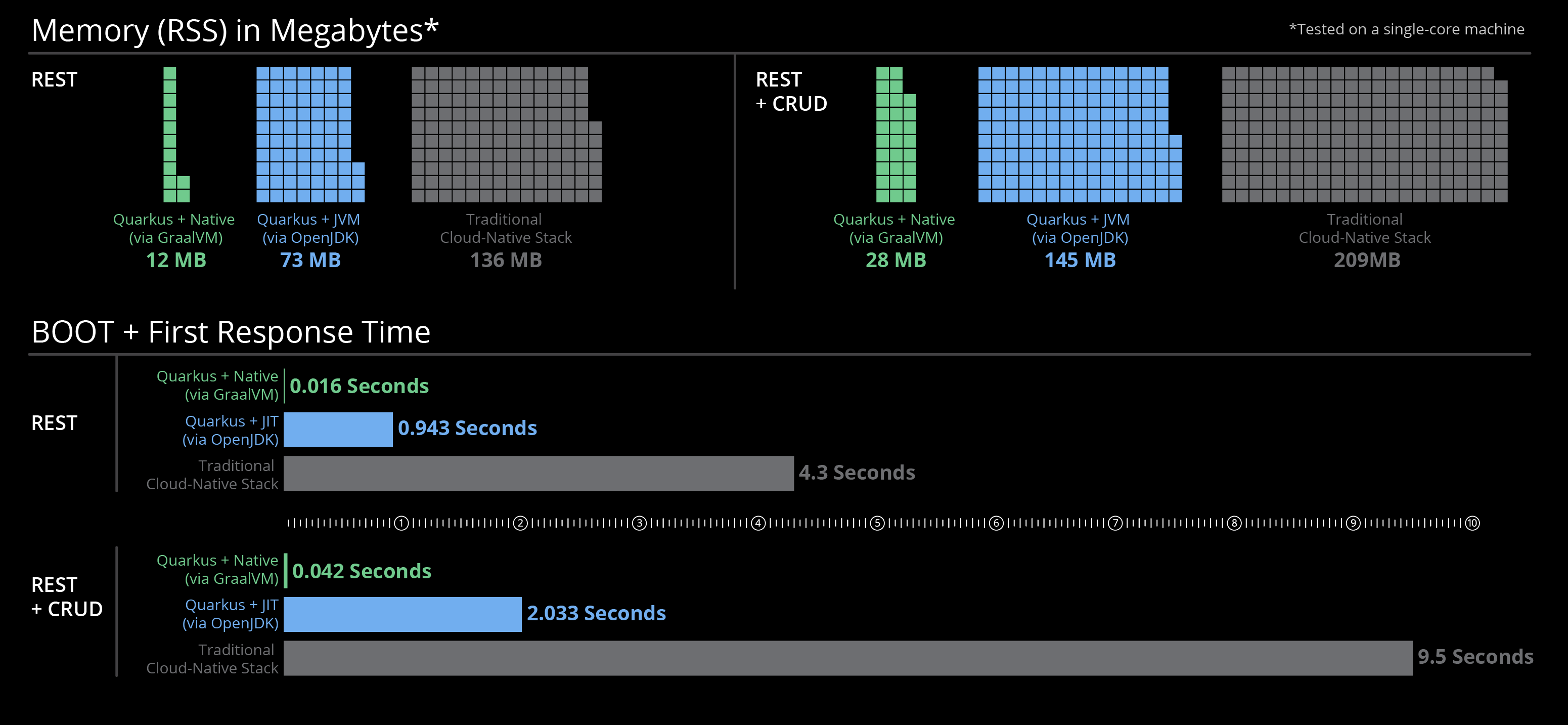
Quarkus 를 이용한 자바 애플리케이션 빌드 실행 시간 실험은 다음과 다음 결과로 요약됩니다.
| 빌드 결과물 | 시작 시간 | 설명 |
|---|---|---|
| Jar 패키지 | 0.325 초 | 초당 3 개 애플리케이션 실행 가능 |
| Native image | 0.013 초 | 초당 80 개 애플리케이션 실행 가능 |
| Container image | 0.027 초 | 초당 40 개 애플리케이션 실행 가능 |
Qurakus 프로젝트 웹 사이트 설명
Quarkus 프로젝트에서 설명한 응답 시간 자료도 이번 실험 결과와 유사한 결과를 설명하고 있었습니다.

애플리케이션 메모리
Jar 애플리케이션
애플리케이션 메모리 상태를 확인하기 위해 Quarkus 를 이용해 빌드한 Jar 애플리케이션의 실행합니다.
$ java -jar target/quarkus-camel-demo-1.0.0-runner.jar
...
다른 실행 창에서 Jar 애플리케이션 메모리 사용을 확인합니다.
$ ps x -o pid,rss,vsz,command | grep quarkus-camel-demo-1.0.0-runner.jar
28338 342832 25454416 /usr/bin/java -jar target/quarkus-camel-demo-1.0.0-runner.jar
상주 메모리는 약 334 MB, 가상 메모리는 약 24 GB 정도 사용하는 것으로 표시됐습니다.
아래는 필자의 개발 PC 자원 모니터링 화면에서 본 Jar 애플리케이션의 메모리 사용 현황입니다.

위 결과는 271.9 MB 로 표시됐습니다.
Native image 애플리케이션
애플리케이션 메모리 상태를 확인하기 위해 Quarkus 를 이용해 생성한 생성한 Native image 애플리케이션을 실행합니다.
$ target/quarkus-camel-demo-1.0.0-runner
...
다른 실행 창에서 Native image 애플리케이션 메모리 사용을 확인합니다.
$ ps x -o pid,rss,vsz,command | grep quarkus-camel-demo-1.0.0-runner
28521 51016 4746796 target/quarkus-camel-demo-1.0.0-runner
상주 메모리는 약 51 MB, 가상 메모리는 약 4.6 GB 정도 사용하는 것으로 표시됐습니다.
아래는 필자의 개발 PC 자원 모니터링 화면에서 본 Jar 애플리케이션의 메모리 사용 현황입니다.

위 결과는 31.3 MB 로 표시됐습니다.
Native image 자바 애플리케이션은 Jar 애플리케이션보다 9 배 정도 적은 메모리로 구동되는 것을 확인 할 수 있었습니다. 그러므로 동일한 기능을 하는 애플리케이션을 Native image 로 빌드해 실행하면 동일 장비에 9 배 이상 밀집도를 갖고 실행 할 수 있으므로, Native image 빌드는 시스템 자원 효율을 9 배 이상 향상시킨다고 볼 수 있습니다.
애플리케이션 실행 메모리 비교
Quarkus 를 이용한 자바 애플리케이 빌드 메모리 사용은 실험은 다음과 다음 결과로 요약됩니다.
| 빌드 결과물 | 사용 메모리 | 설명 |
|---|---|---|
| Jar 패키지 | 334 MB | 일반적인 자바 애플리케이션 사용 메모리 |
| Native image | 51 MB | 6 배 절감된 메모리 사용 |
Qurakus 프로젝트 웹 사이트 설명
Quarkus 프로젝트에서 설명한 메모리 자료도 이번 실험 결과와 유사한 결과를 설명하고 있었습니다.
라즈베리 파이(Raspberry PI)
자바 애플리케이션을 적은 메모리로 빠르게 실행할 수 있다면 , 라즈베리 파이 같은 사물 인터넷(IOT) 장비의 언어로 자바 언어가 상당히 매력적인 언어가 될 수 있을 것입니다. 필자는 이런 생각을 기반으로 Quarkus 개발 환경을 라즈베리 파이에 구성해 동일한 애플리케이션을 빌드해 시도해 보았습니다. 그러면서 아래와 같은 문제를 만났습니다.
- 라즈베리 파이 32bit OS
- ARM 프로세서
- 시스템 메모리 한계 (최대 4 GB)
위 문제 중 32bit OS 문제는 라즈베리파이 용 Ububtu 64bit OS 를 설치해서 해결했고, ARM 프로세서 문제는 ARM 기반 Open JDK 11, GraalVM 을 설치해 해결했습니다. 그러나 시스템 메모리 부족 문제로 Native image 빌드는 라즈베리 파이 내에서 완료할 수 없었습니다. (그 이유는 Native image 빌드를 위해서는 14 G 이상의 시스템 메모리가 필요하기 때문입니다.) 그러나 ARM 기반 서버도 최근에는 쉽게 구할 수 있으므로 메모리가 충분한 ARM 기반 서버에서 Native image 를 생성해 라즈베리파이에서 실행하면 되므로 굳이 라즈베리 파이에서 Native image 빌드까지 하지 않더라도 활용하는 대는 문제가 없을 것으로 보입니다. 그러므로 자바 언어는 라즈베리 파이와 같은 IOT 영역에서도 곧 큰 힘을 발휘할 때가 올 것으로 전망합니다.
다음은 라즈베리 파이에서 Quarkus 로 통합 애플리케이션을 빌드한 결과입니다.
$ ls -alh target/
...
-rw-rw-r-- 1 ubuntu ubuntu 278K 5월 4 13:25 quarkus-camel-demo-1.0.0-runner.jar
-rw-rw-r-- 1 ubuntu ubuntu 8.9K 5월 4 14:12 quarkus-camel-demo-1.0.0.jar
drwxrwxr-x 2 ubuntu ubuntu 16K 5월 4 13:25 lib
...
$ du -sh target/lib
37M target/lib
Quarkus 로 Jar 실행 패키지 빌드 결과는 macOS 나 CentOS 나 크게 다르지 않았습니다. 이 결과는 자바 언어가 플랫폼 독립적이라는 점을 잘 보이고 있는 것입니다.
다음은 라즈베리 파이에서 Jar 패키지 통합 애플리케이션을 실행한 결과입니다.
$ java -jar target/quarkus-camel-demo-1.0.0-runner.jar
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
--\___\_\____/_/ |_/_/|_/_/|_|\____/___/
2020-05-05 01:32:44,508 INFO [org.apa.cam.sup.LRUCacheFactory] (main) Detected and using LURCacheFactory: camel-caffeine-lrucache
2020-05-05 01:32:49,434 INFO [org.apa.cam.mai.BaseMainSupport] (main) Auto-configuration summary:
2020-05-05 01:32:49,438 INFO [org.apa.cam.mai.BaseMainSupport] (main) camel.context.name=quarkus-camel-demo
2020-05-05 01:32:49,669 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Apache Camel 3.1.0 (CamelContext: quarkus-camel-demo) is starting
2020-05-05 01:32:49,682 INFO [org.apa.cam.imp.eng.DefaultManagementStrategy] (main) JMX is disabled
2020-05-05 01:32:50,590 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) StreamCaching is not in use. If using streams then its recommended to enable stream caching. See more details at http://camel.apache.org/stream-caching.html
2020-05-05 01:32:52,444 INFO [org.apa.cam.com.htt.HttpComponent] (main) Created ClientConnectionManager org.apache.http.impl.conn.PoolingHttpClientConnectionManager@2436ea2f
2020-05-05 01:32:53,352 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Route: csvProducerRoute started and consuming from: timer://csv
2020-05-05 01:32:53,390 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Route: csvConsumerRoute started and consuming from: file://input
2020-05-05 01:32:53,416 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Total 2 routes, of which 2 are started
2020-05-05 01:32:53,428 INFO [org.apa.cam.imp.eng.AbstractCamelContext] (main) Apache Camel 3.1.0 (CamelContext: quarkus-camel-demo) started in 3.749 seconds
...
라즈베리 파이에서 애플리케이션의 시작 시간은 3.749 초가 걸렸습다. 개발 PC 의 시작 시간 0.325 초에 비해 길지만 라즈베리 파이 환경에서 4초 이내 자바 애플리케이션이 완전히 실행됐다는 점에서 의미있는 시작 시간으로 볼 수 있습니다.
필자는 별도의 ARM 서버를 준비하지 못해, 라즈베리 파이에서 Native image 애플리케이션을 실행해 보지 못했지만, Native image 자바 애플리케이션을 라즈베리 파이에서 실행한다면, 시작 시간은 1초 이내고 메모리도 수십 MB 로 실행될 것을 예상할 수 있을 것입니다. 이 정도 실행 속도와 자원 사용 환경이라면, IOT 에서도 충분히 의미있는 애플리케이션을 개발, 운영할 수 있을 것입니다. 즉 자바 언어가 만든 유용한 라이브러리와 프레임워크 등을 IOT 영역에 도입하는데 큰 장애물이 사라졌다고 볼 수 있을 것입니다.
참고로 ARM 서버는 Amazon EC2 A1 인스턴스 에서 저렴하게 임대할 수 있습니다. 라즈베리 파이에서 Native image 자바 애플리케이션 실행의 검증은 관심있는 독자에게 맡깁니다.
맺음말
GraalVM 이 등장하면서, 자바 컴파일 방식에 큰 발전이 일어났습니다. 지금까지 자바 컴파일러가 바이트 코드를 생성했다면, GraalVM 컴파일러는 바이트 코드 뿐만 아니라, native image 를 생성할 수도 있게 됐습니다. 이에 따라 native image 자바 애플리케이션은 C 나 Golang 언어만큼 시작 속도와 메모리 사용이 빨라지고 작아지게 됐습니다.
지금까지 자바 언어는 JVM 에 의존하면서 서버 애플리케이션이으로서 탄탄한 상태계를 구축했지만, 컨테이너 시대가 도래하고, 새로운 언어들이 등장하고 발전하는 데, 느린 시작 시간과 많은 메모리 사용으로 유용성이 제한되는 문제가 있었습니다. 그러나 이제는 자바 언어가 native image 로 동작 가능하게 되면서, 컨테이너 시대에도 빠른 시작 시간과 적은 메모리 사용으로, 주력 언어의 지위를 계속 이어 갈 수 있게 됐습니다.
Quarkus 는 자바 언어를 컨테이너 시대에 사용하기 편리하게 해주는 프레임워크입니다. Spring Boot 가 웹 서버를 내장하면서 WAS(Web Application Server) 를 벗어나 자바 MSA(Microservice Architecture) 에 주력 프레임워크가 됐듯이, Quarkus 는 현재도 여전히 발전하는 프로레임워크로 Spring Boot 와 유사한 기능을 제공하고, native image 빌드를 위한 확장을 제공하므로, 컨테이너 MSA 환경에서 중요한 프레임워크가 될 것으로 기대해 봅니다.
Apache Camel 은 EIP(Enterprise Integration Patters) 의 구현체인 통합 프레임워크로 Spring Boot 뿐만 아니라 Quarkus 와도 잘 결합돼 컨테이너 MSA 환경에서 레거시 통합 및 MSA 통합에 주요한 프레임워크입니다. 더불어 Qurakus 기술과 결합해 MSA 통합에서 IOT 통합까지 다양한 응용 분야에서 중요한 기술로서 가능성이 있습니다.
필자가 GraalVM 기술을 처음 접했을 때, 왜 이 기술이 나올 때까지 20년 (자바 언어는 1995년 탄생) 이상이 걸렸는지 의아하기도 하고 또 반가웠습니다. 이제 자바로 Golang 처럼 빠른 실행과 적은 메모리를 사용하는 애플리케이션을 개발할 수 있다는 점은 자바 언어가 앞으로 10년 이상 건재할 것이라는 것을 의미하기 때문입니다.
GraalVM, Quarkus, Apache Camel, 그리고 Spring Boot 도 자바를 native image 세계로 인도하고 있습니다. 물론 아직은 완전히 성숙됐다고 볼 수 없어 실제 기술 검토를 하면, 여러 가지 문제를 만나게 됩니다. 그럼에도 지속적으로 발전하고 편해지고 있습니다. 그 중 Red Hat 은 Quarkus 와 Apache Camel 을 서브스크립션을 통해 기술 지원하므로 커뮤니티 오픈소스를 직접 사용함에 따른 다양한 시행착오와 기술 문제의 해결을 지원 받을 수 있다는 점은, 이 기술에 관심을 가진 기업이 비즈니스 애플리케이션에 이용하는 데 장벽을 낮춰줄 수 있을 것입니다. 이 글을 읽는 독자가 이 새로운 변화에 관심을 갖는다면 분명 이 시대 누구보다 앞선 엔지니어가 될 수 있을 것입니다.
사마천 사기 상군(商君) 열전 에 이런 말이 나옵니다.
기구일지라도 그 효용이 10 배가 되는 것이 아니면 바꾸지 않는 법이다.
끝으로 GraalVM 과 Qurakus 그리고 Apache Camel 의 결합은 10 배 이상의 효용을 줄 수 있을 것이라 감히 이야기 해봅니다.
참고 자료
- Quarkus Apache Camel Demo Source
- GraalVM
- GraalVM Downloads
- Quarkus
- Red Hat Qurakus
- Quarkus Getting Started
- Quarkus Code Starter
- Apache Camel
- Red Hat Fuse
- Camel in Action
- 기업 통합 패턴(Enterprise Integration Patterns)
- 바른모 블로그
- Spring Boot
- CentOS
- Raspberry PI
- Ubnutu server on Raspberry PI
- Docker desktop
- Windows 10 WSL2 설치 지침
- Amazon EC2 A1 인스턴스